Abstract
Deep learning weather models now match numerical weather prediction accuracy while running orders of
magnitude faster, but produce deterministic forecasts without uncertainty estimates, a critical gap
for high-stakes decisions during extreme weather events. We propose Neural Tangent Kernel-based uncertainty
quantification (NTK-UQ) using last-layer empirical features. Theory predicts that UQ
quality is architecture-dependent through two mechanisms. First, a variance collapse mechanism
explains when UQ fails: when the eigenvalue truncation rank approaches the effective rank of the feature
space, the GP correction consumes nearly all prior variance, destroying discrimination between tropical
cyclones and routine conditions. Second, decomposition performance depends on the non-Gaussian, heavy-tailed
structure of extreme weather: Independent Component Analysis (ICA) exploits higher-order statistics to
isolate heavy-tailed extreme-event features, beating singular value decomposition (SVD), which captures
only second-order variance. A data-driven rule selects ICA or SVD from the feature eigenspectrum, correctly
prescribing the superior decomposition for all four evaluated models. Against split conformal prediction,
NTK-UQ achieves 31–37% sharper intervals at 90% coverage and uniquely produces adaptive intervals
that scale with event severity.
31–37%
sharper intervals than conformal,
at 90% coverage
4
frozen foundation models
(SFNO, Swin Transformer,
Perceiver IO, GNN)
<10 ms
real-time UQ, no retraining,
no extra GPU memory
Method Overview
Figure 1. Atmospheric variables from extreme-weather events pass through a frozen
foundation weather model to extract last-layer features. These build the empirical Neural Tangent Kernel,
decomposed via SVD or ICA (\(U\Sigma V^\top\)) to a rank-\(k\) approximation. At inference, the GP
posterior variance yields calibrated prediction intervals per variable.
NTK-UQ treats a frozen model's last-layer features \(\phi(x)\) as an empirical kernel and returns
the Gaussian-process posterior variance per output variable:
\[ K(x, x') = \phi(x)^\top \phi(x'), \qquad
\sigma^2(x_*) = \bigl\lVert \tilde{\phi}(x_*) \bigr\rVert^2 + \sigma_n^2
- \sum_{j=1}^{k} \frac{\lambda_j\, c_j^2}{\lambda_j + \sigma_n^2}. \]
Here \(c_j = \tilde{\phi}(x_*)^\top v_j\) projects the centered test feature onto the
\(j\)-th kernel eigenvector \(v_j\) (eigenvalue \(\lambda_j\)), and \(\sigma_n^2\) is the noise variance.
A post-hoc scale \(\alpha\) calibrates the interval width per variable.
Results
Across 17 variables × 6 lead times × 4 models on a census of 100 EM-DAT extreme-weather events
from 2021. Bold marks the decomposition satisfying the 85–95% coverage constraint;
conformal prediction is a reference baseline (never highlighted).
ICA vs SVD at optimal rank \(k^*\) (2m temperature)
| Model | Method | \(k^*\) | Coverage | Sharpness (\(\sigma\)) | CRPS |
|---|
| AIFS | ICA | 7 | 90.6% | 168.9 | 129.8 |
| AIFS | SVD | 50 | 90.9% | 144.8 | 133.5 |
| Aurora | ICA | 50 | 90.1% | 602.1 | 701.4 |
| Aurora | SVD | 2 | 58.1% | 11.8 | 935.2 |
| FourCastNetV2 | ICA | 3 | 89.5% | 103.2 | 61.5 |
| FourCastNetV2 | SVD | 1 | 89.5% | 66.3 | 64.5 |
| Pangu-Weather | ICA | 40 | 68.4% | 1706 | 20133 |
| Pangu-Weather | SVD | 40 | 91.1% | 35529 | 14361 |
ICA satisfies coverage for 3 of 4 models with lower CRPS; SVD wins only for Pangu-Weather, whose 69-dim pooled features are inherently low-rank.
NTK-UQ vs conformal prediction: mean \(\sigma\) (coverage)
| Variable | Model | Lead | NTK-UQ (best) | Conformal | Sharper |
|---|
| 2m temp (K) | AIFS | 24h | 1.98 (91%) | 2.86 (90%) | 31% |
| 2m temp (K) | FourCastNetV2 | 24h | 1.55 (89%) | 2.33 (100%) | 33% |
| MSL (Pa) | AIFS | 24h | 524 (91%) | 776 (95%) | 32% |
| MSL (Pa) | FourCastNetV2 | 24h | 140 (89%) | 211 (90%) | 34% |
NTK-UQ achieves lower \(\sigma\) than conformal in 81% of valid comparisons (230/284), at matched \(\approx\)90% coverage.
Adaptivity: coefficient of variation at t+6h (higher = more adaptive)
| Model | CV t2m (ICA) | CV t2m (SVD) | CV msl (ICA) | CV msl (SVD) |
|---|
| AIFS | 0.27 | 0.05 | 0.27 | 0.05 |
| FourCastNetV2 | 0.31 | 0.06 | 0.31 | 0.00 |
| Aurora | 0.09 | 0.10 | 0.09 | 0.10 |
| Pangu-Weather | 1.81* | 0.49 | 0.09 | 0.49 |
ICA yields ~5× higher CV than SVD for AIFS and FourCastNetV2, i.e. intervals that scale with event severity. *Pangu-ICA is excluded (68.4% coverage).
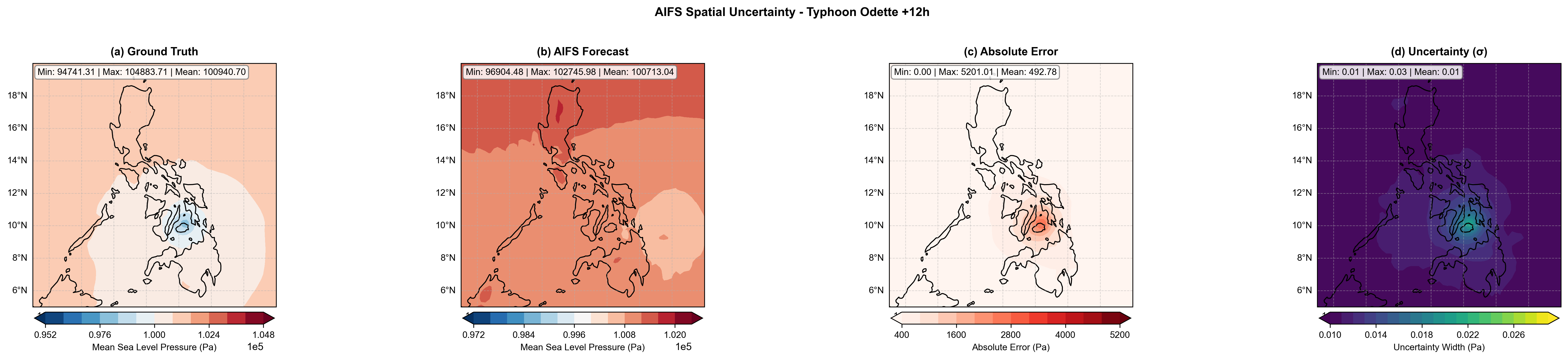
Spatial Uncertainty
Figure 2. AIFS spatial uncertainty for Typhoon Odette (2021-12-16, Philippines), t+12h.
The NTK-UQ uncertainty map (right) concentrates near the cyclone track, aligning with forecast error
to enable targeted warnings for landfall zones rather than uniform domain-wide alerts.