Quantitative Results
Physics-residual MSE (lower is better) across systems and generalization regimes, plus Koopman diagnostics.
Best per row in blue. Full results for all systems are in the
repository.
Summary of Key Improvements over the PINN Baseline (grouped by metric type)
†Bounded-domain problems where spatial extrapolation demonstrates model capability rather than
physical prediction. Improvement = PINN MSE / best-method MSE (higher is better).
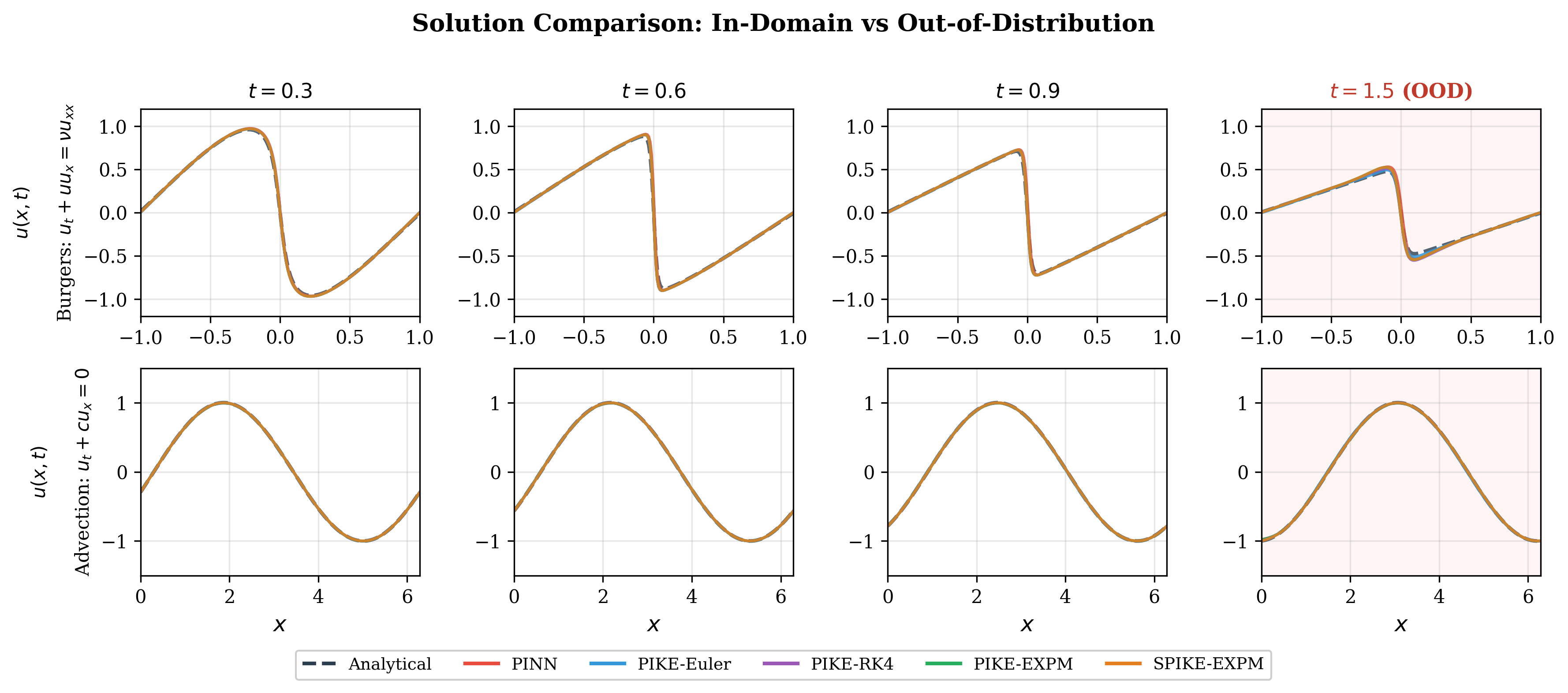
1D PDEs — In-Domain Physics Residual MSE (x, t ∈ [0,1])
1D PDEs — Spatial Extrapolation (OOD-Space) (x ∈ [1,3], t ∈ [0,1])
1D PDEs — Temporal Extrapolation (OOD-Time) (x ∈ [0,1])
2D PDEs — In-Domain Physics Residual MSE (x, y, t ∈ [0,1])
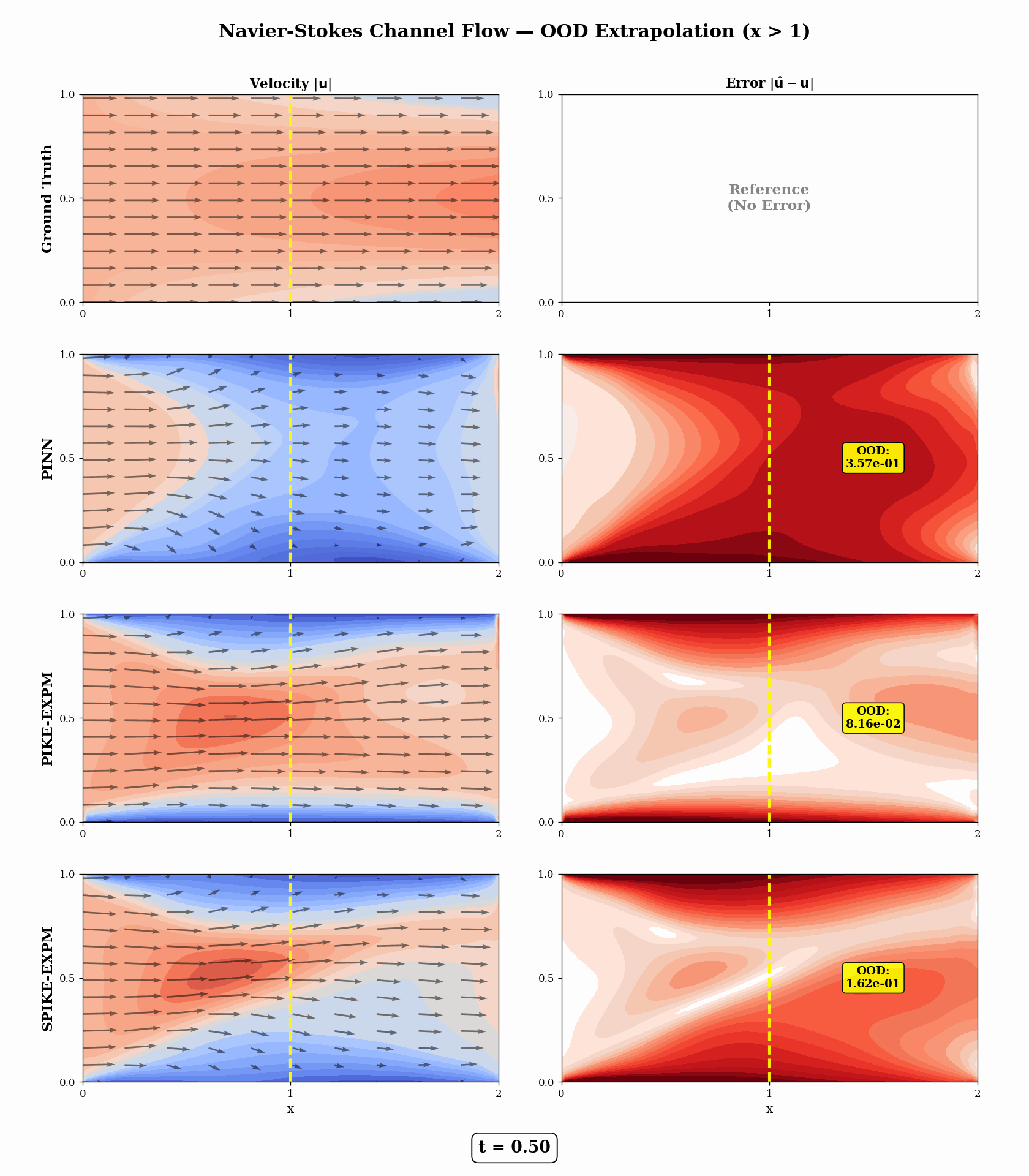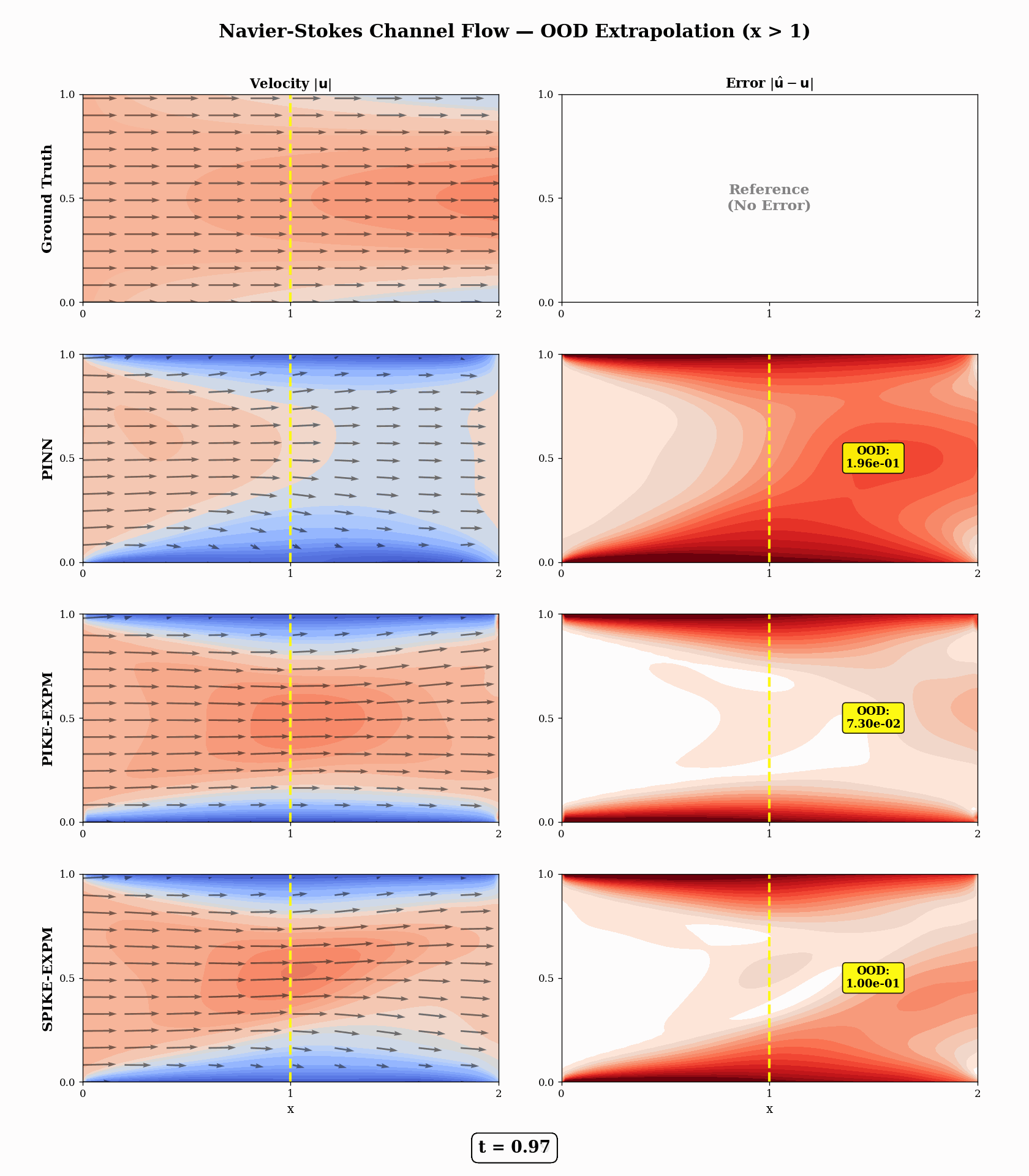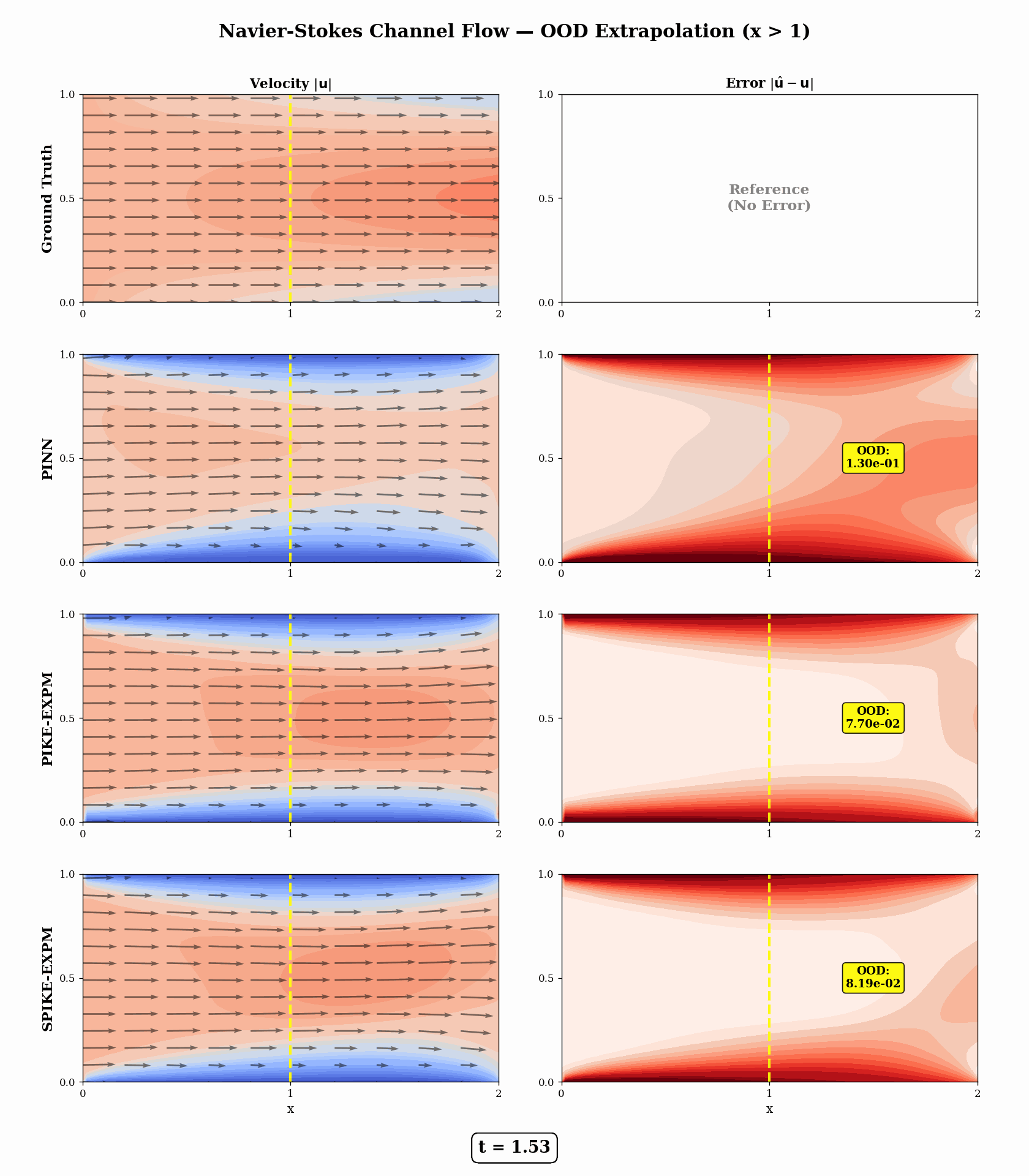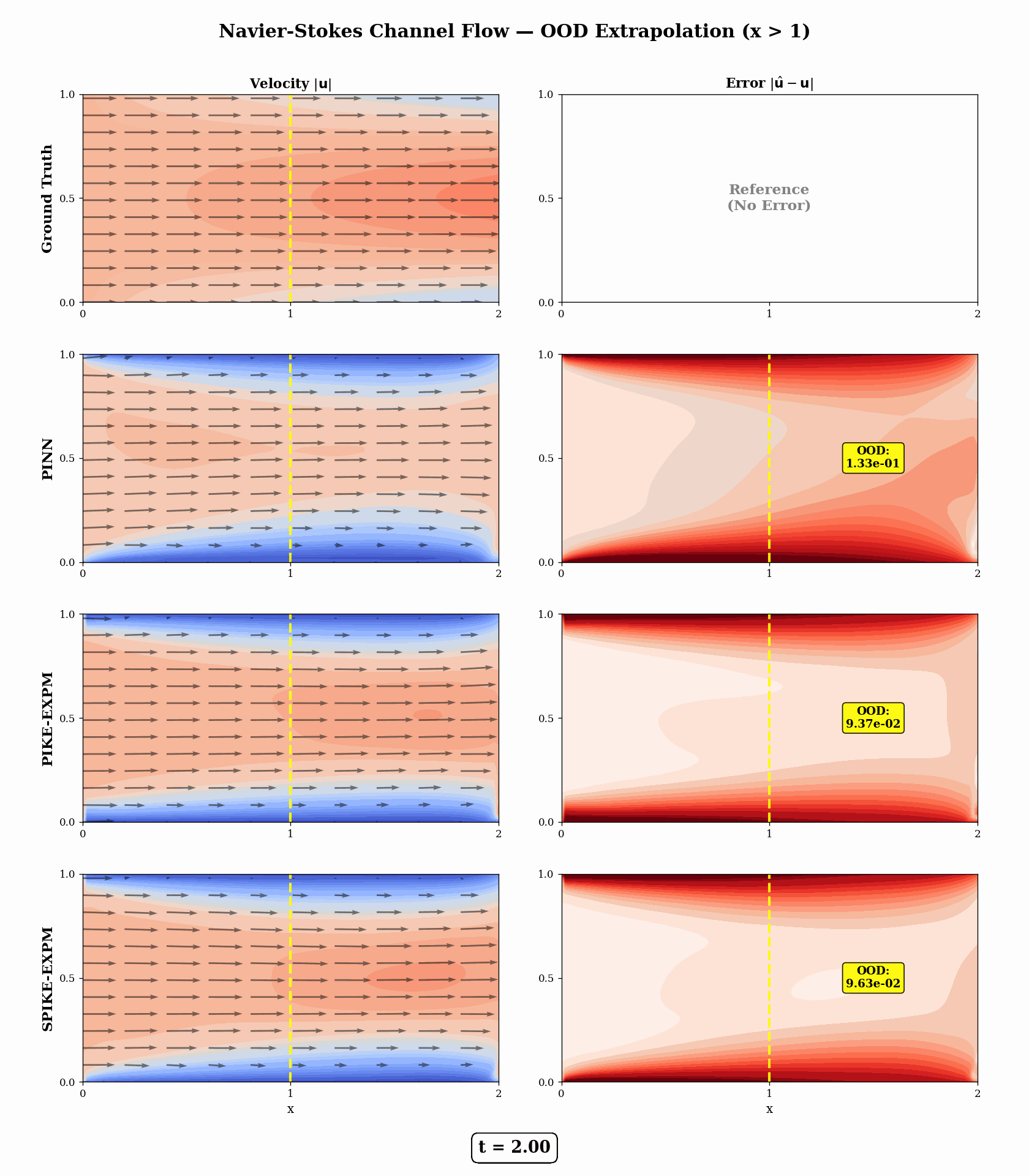
Navier–Stokes — Downstream Channel Flow (physically meaningful OOD, t = 0.5)
PIKE-EXPM achieves a 5.5× lower OOD-downstream MSE than PINN (7.14e-2 vs 3.94e-1).
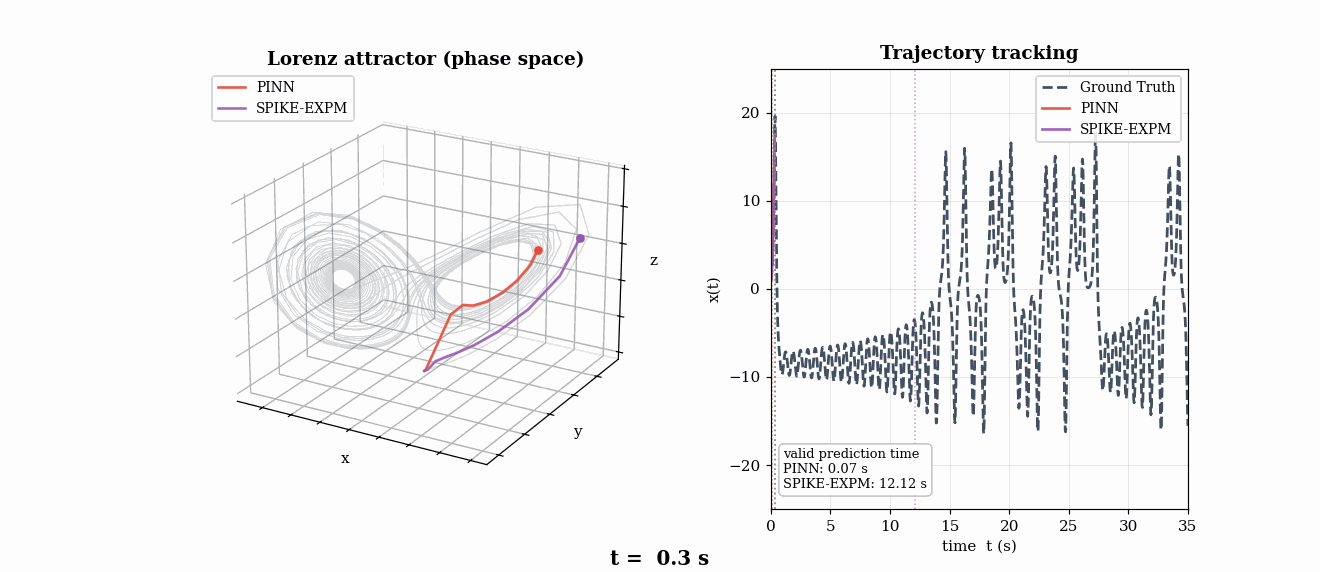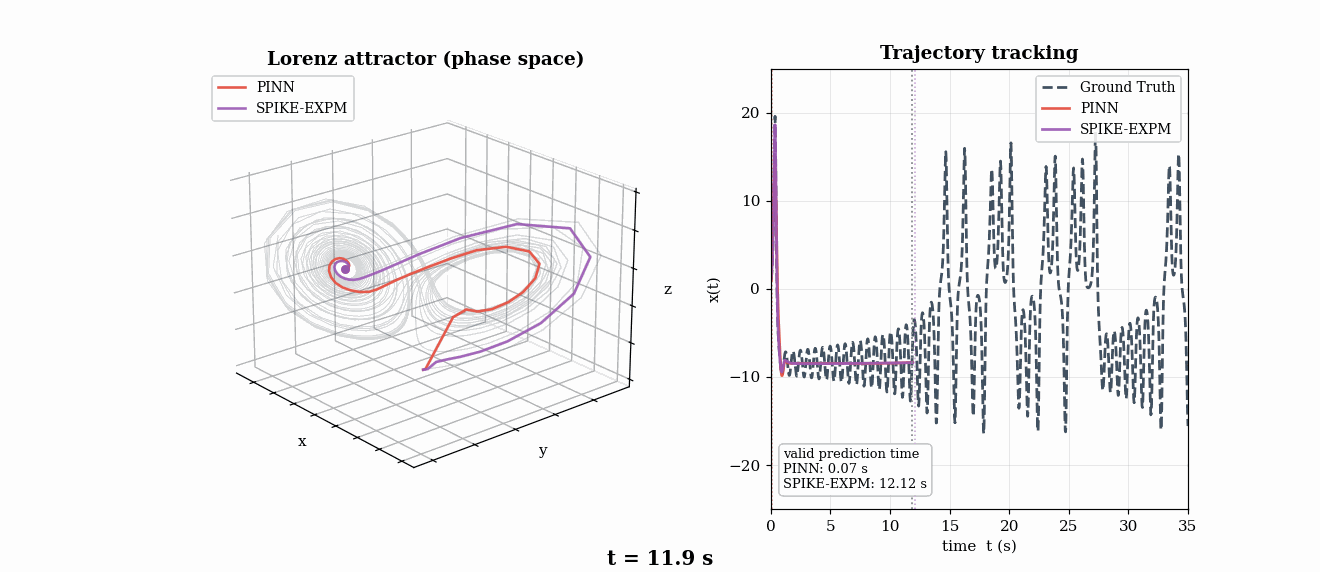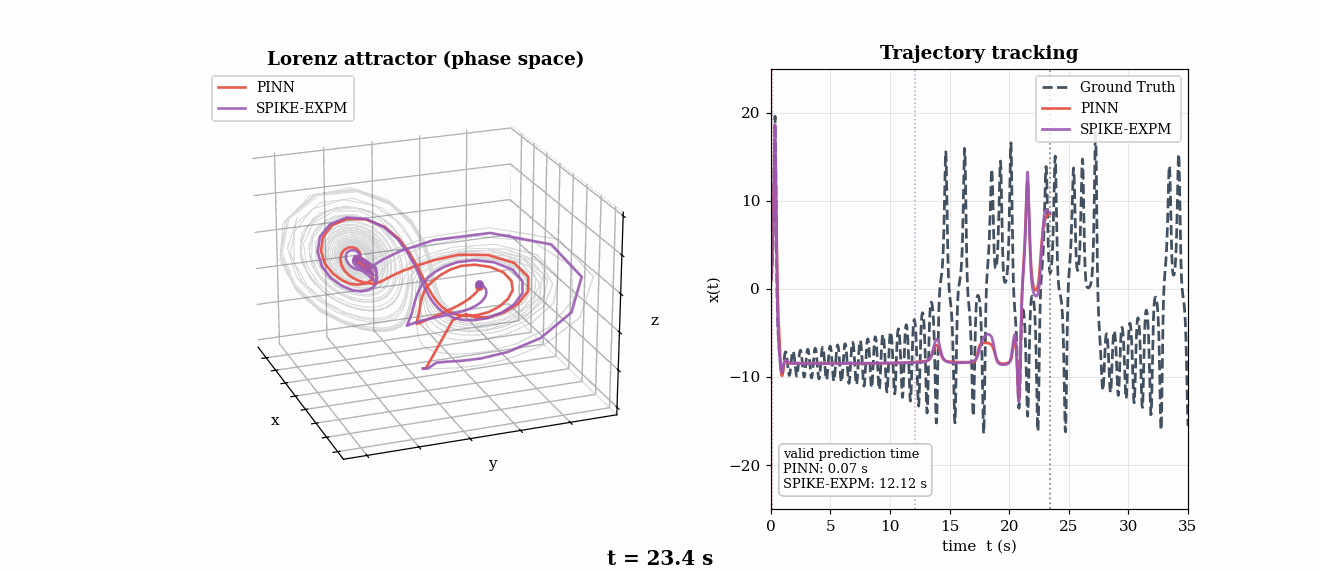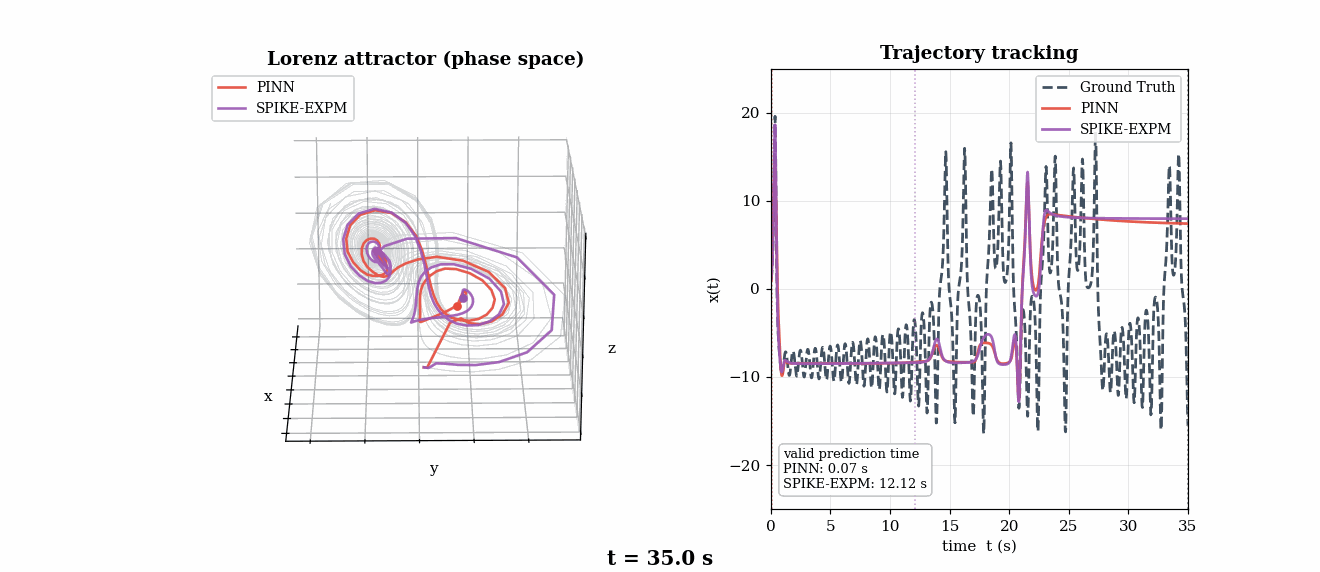
Chaotic Dynamics — Lorenz Lyapunov Analysis (τλ = 1.1 s)
Koopman Latent R² (higher is better; PIKE/SPIKE only)
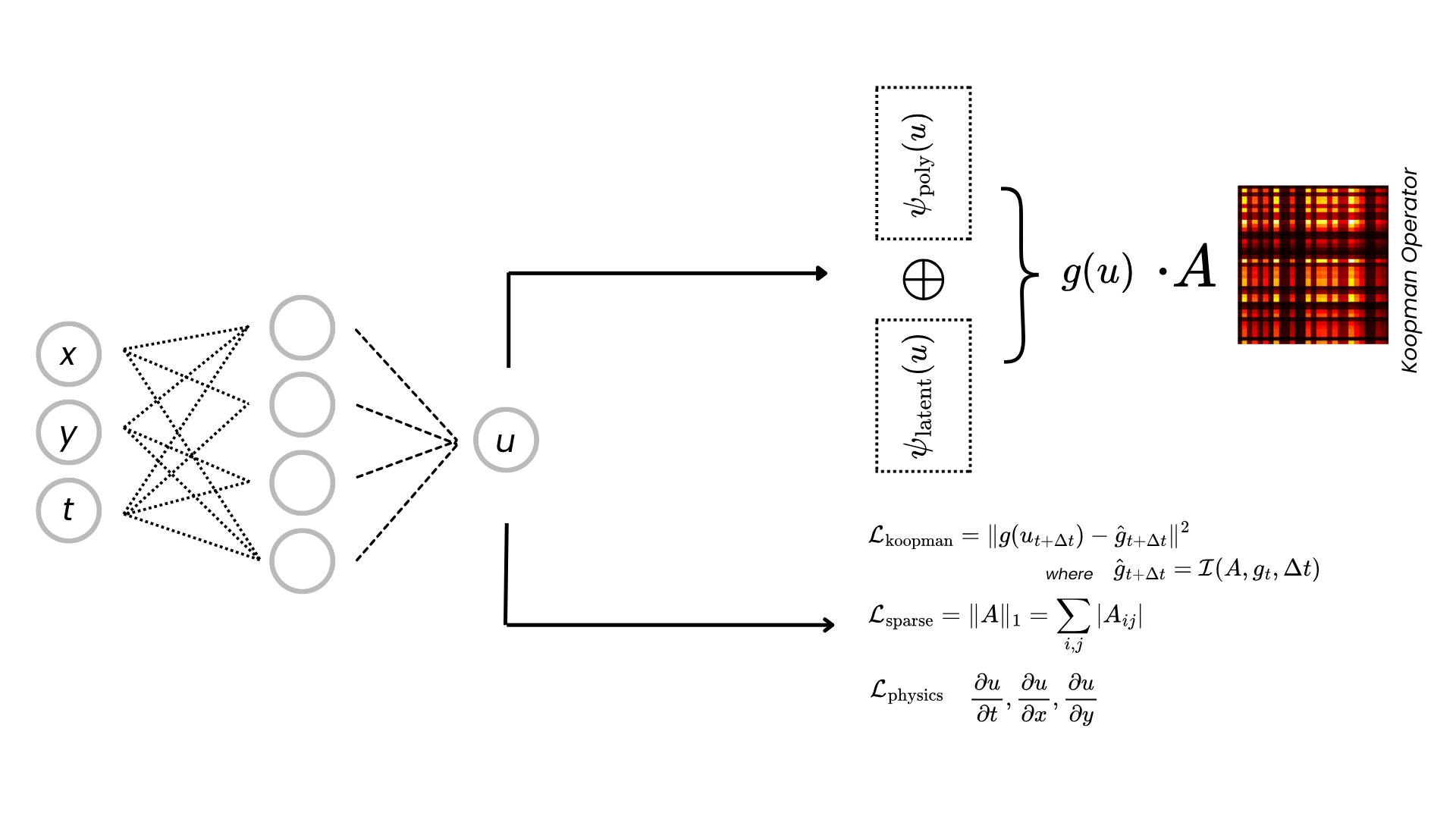
Learned Dynamics Structure (interpretability: library term + latent correlations)
Observable convention g0 = 1, g1 = u, g2 = u². Bold marks strong latent
correlations (|r| > 0.7). The sparse generator recovers interpretable structure: SPIKE's L1 penalty makes
Kuramoto-Sivashinsky 4× sparser while preserving the dominant u³ coupling.